Towards SOTA Forecasting LLMs
High-stakes decisions in policy, investing, and risk management require reasoning about the future under uncertainty. Language models can ingest and synthesize vast information across thousands of topics, making them natural candidates. But off-the-shelf LLMs are weak forecasters: they are overconfident, poorly calibrated, and rarely trained to reason probabilistically about open-ended outcomes. Recent benchmarks show the gap closing: the best LLMs now achieve Brier scores within range of human superforecaster panels,[4] with parity projected by late 2026.[5]
Most prior work focuses on binary yes/no prediction market questions (e.g. "Will X win the election?"), where a coin flip already gets you 50% accuracy. The harder and more valuable task is open-ended forecasting: predicting who, what, or where without a fixed set of choices. This is the setting we train for.
Eternis-Forecaster-8B (EF-8B)
We train an 8B-parameter language model to make open-ended predictions about world events. On the OpenForesight benchmark (302 questions, May–August 2025), EF-8B surpasses all published baselines including OpenForecaster-8B,[1] a recent open-source system that itself matched proprietary models like GPT-OSS-120B and DeepSeek-R1 in Brier score and accuracy. The right reinforcement learning harness lets post-training alone consistently beat models 10-15x larger in parameter count.
Each question is paired with retrieved news context from up to one month before the event resolves, ensuring no future information leaks into the prediction. The model must reason about what it knows, weigh competing signals, and produce both an answer and a calibrated probability.
Method
Context building. The quality of retrieved context is the single largest driver of forecasting accuracy. Our tailor-made context-building pipeline mirrors how a skilled forecaster prepares: iteratively searching, evaluating relevance, and synthesizing from a large corpus. It combines structured search with calls to the best reasoning models to curate the most decision-relevant passages — improving accuracy without any weight changes.
Reward design for uncertainty. Standard RL rewards in language model training treat correctness as binary: right or wrong. Forecasting demands more. We modified the reward function so the model is incentivized to take calibrated risks: making bold predictions when evidence supports it and hedging appropriately when it doesn't. The model is rewarded for how confidently right it is, and penalized more harshly for confident mistakes than for uncertain ones.
Modified GRPO training. We adapted the Group Relative Policy Optimization (GRPO) algorithm[2][3] itself to better suit the forecasting setting. In standard GRPO, all errors are treated roughly equally during policy updates. Our modifications introduce asymmetry: highly confident incorrect predictions receive disproportionately strong penalties, while highly confident correct predictions receive the largest rewards. This reshapes the optimization landscape to favor well-calibrated, exploratory reasoning.
Results
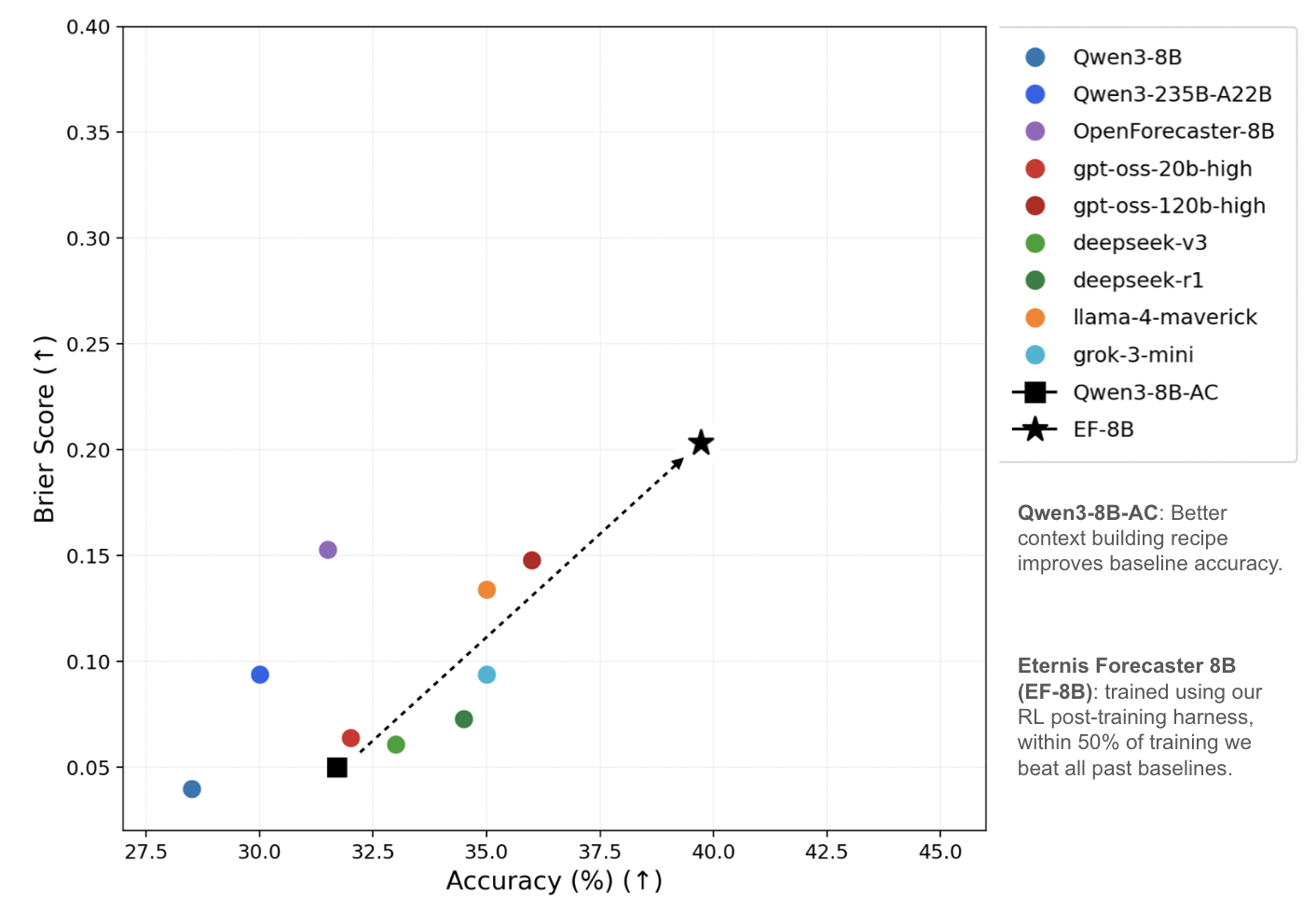
At 40% of training, EF-8B already matches or exceeds all prior baselines on the OpenForesight test set across both accuracy and Brier score. The model achieves this at 8B parameters: orders of magnitude smaller than the other models it competes with. Calibration improvements from our training also generalize to out-of-distribution benchmarks, suggesting the model has learned genuinely transferable probabilistic reasoning rather than dataset-specific shortcuts.
What the model learned
The following examples compare the base model against the 40% training checkpoint — the same checkpoint that already surpasses all published baselines.
Better domain reasoning. When asked "Which hazardous material will be a concern at the site of the contentious Belfast bonfire during the upcoming multi-agency risk assessment?" (right answer is asbestos), the base model confidently answered "tyres" at p=0.82, reasoning that multiple articles about bonfires mentioned tyre dumping. EF-8B instead answered "asbestos" at p=0.37, reasoning that asbestos is a regulated hazardous substance found in building materials, unlike tyres which are waste but not technically hazardous. It got the right answer while becoming less overconfident.
Reasoning past the obvious. For "Which northeastern Ukrainian city will President Putin say his forces may take control of as part of a buffer zone by the end of June 2025?" (right answer is Sumy), the base model defaulted to "Kharkiv," the most prominent northeastern Ukrainian city in news coverage. EF-8B's reasoning explicitly considered that Kharkiv is a major city unlikely to be framed as a buffer zone target, and worked through alternatives in the northeast, landing on "Sumy," the correct and less obvious answer. Similarly, asked "Which country's flag will MV Wan Hai 503 be flying when it suffers the explosion off Kerala?" (right answer is Singapore), the base model answered "Taiwan" because Wan Hai Lines is a Taiwanese shipping company. EF-8B distinguished between company headquarters and flag state, noting that Asian shipping companies often register under flags of convenience, and correctly answered "Singapore."
Convergence on already-known answers. For many questions, the base model already had the right answer in 1 out of 3 samples but was inconsistent. For example, asked "Who will visit London in early July 2025 to unveil the UK-France migration deal?" (answer: Emmanuel Macron), the base model produced ["Unknown", "Unknown", "Emmanuel Macron"]. Two out of three samples gave up and said Unknown. EF-8B consistently output "Emmanuel Macron" across all three samples, reasoning directly instead of giving up. The same pattern appeared for "Which Republican Senator from Kentucky will be recorded as voting against the bill in the Senate roll call?" (answer: Rand Paul). The base model split between Rand Paul and Mitch McConnell, but EF-8B consistently chose Rand Paul noting Paul's record of voting against party-line bills.
Across all net-gained questions, the model's average predicted probability actually decreased (0.39 to 0.27), showing it learned calibration rather than gaming confidence. It got more answers right while simultaneously becoming more honest about its uncertainty.
Given the positive results above, we are now scaling up post-training with the goal of matching the best reasoning models on general-purpose forecasting at a fraction of the cost — allowing us to maintain cheap, continually learning world models. More on this soon.
References
[1] N. Chandak et al., "Scaling Open-Ended Reasoning to Predict the Future," arXiv:2512.25070 (2025).
[2] Z. Shao et al., "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models," arXiv:2402.03300 (2024).
[3] D. Guo et al., "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning," arXiv:2501.12948 (2025).
[4] J. Lu et al., "Evaluating LLMs on Real-World Forecasting Against Expert Forecasters," arXiv:2507.04562 (2025). Best LLM Brier score 0.135 vs. superforecaster panel 0.122.
[5] ForecastBench, "How Well Can Large Language Models Predict the Future?" Forecasting Research Institute (2025). GPT-4.5 achieves Brier 0.101 vs. superforecasters' 0.081.
